





































在网络安全态势日趋复杂的背景下,传统的城市级IP定位已难以满足精细化风控需求。一个典型的痛点:攻击者使用同一城市内的代理IP绕过风控,城市级定位无法区分正常用户与欺诈流量。而街道级IP定位配合离线IP数据库部署,能够将IP位置的识别粒度大幅提升,从而显著增强IP欺诈风险查询的准确性和响应速度。本文将围绕这一主线,提供一套可落地的完整方案。
为什么城市级定位不够用
普通IP归属地查询只能到城市级别。这意味着,来自北京朝阳区的正常用户和同样显示"北京市"的欺诈代理IP,在传统风控系统中几乎没有差异。攻击者正是利用这种粗粒度,通过同城代理、机房IP伪装等手段绕过检测。
根据艾瑞咨询《2024年中国网络安全行业研究报告》,超过63%的风控团队表示,城市级IP信息在识别同城代理攻击时"基本失效"。这一数据直观说明,引入街道级IP定位能力是提升风控效果的关键方向。
什么是街道级IP定位
街道级IP定位,指将IP地址映射到街道或更细粒度地理位置的定位服务。相比城市级定位(精度约10-50公里),街道级定位的精度通常可提升至1-5公里范围,能有效区分同一城市内不同区域的IP来源。
实现街道级IP定位依赖于多源数据的深度融合,包括:
- ISP的IP地址分配脉络
- 主动探测的网络延迟特征
- 经过脱敏处理的用户校准样本
- 路由节点拓扑分析
在金融交易风控、广告反作弊、外卖配送地址校验等场景中,街道级IP定位的能量半径显著缩小,为业务判断提供了更有价值的空间参考。
离线IP数据库部署的核心价值
将街道级定位能力部署在本地环境,即离线IP数据库部署,是企业级IP风控的常见做法。其核心优势体现在:
数据不出网,合规性更强
金融、政务等行业对数据安全有严格要求。离线IP数据库部署将所有查询闭环在自有服务器或私有云环境,IP数据不离开企业网络,满足数据安全与合规审计的双重要求。
响应速度大幅提升
在线API查询的网络往返延迟通常在数十毫秒级别,高并发下还可能排队。本地部署的离线库查询延迟可降至微秒级,在实时风控场景中,每一笔交易的风险判定窗口极为有限,低延迟是刚需。
查询成本可控、容量无上限
订阅在线API服务时,查询量越大费用越高,且面临QPS(每秒查询数)上限。通过离线IP数据库部署,一次采购即可在自有服务器上无限量查询,尤其适合日均查询量达到数千万甚至亿级的大型平台。

街道级离线库部署实战步骤
以下是完成离线IP数据库部署的典型流程:
第一步:选型评估
选择支持街道级IP定位的离线IP数据库产品时,重点评估以下维度:
- 覆盖范围:全球还是国内,IPv4与IPv6是否双栈
- 精度等级:是否支持街道级定位
- 数据格式:二进制.dat格式(查询快)还是文本.csv格式(可读性强)
- SDK支持:Java/Python/Go等语言SDK是否完善
- 更新频率:提供按周或按月更新的增量包
第二步:服务器环境准备
建议配置:
- 内存:IP库通常需加载到内存中以保证查询速度,街道级库文件较大,建议预留16GB以上内存
- 存储:SSD优先,用于存放库文件和增量更新数据
- 网络:仅用于定期拉取更新包,查询过程不依赖外网
第三步:库文件加载与初始化
以Java SDK为例,典型加载代码:
IPDatabase db = IPDatabase.builder()
.dataPath("/data/ipdb/ipv4_street_level.dat")
.cacheSize(4096)
.build();
// 查询示例
IPResult result = db.query("192.168.1.1");
System.out.println(result.getCountry()); // 中国
System.out.println(result.getProvince()); // 广东省
System.out.println(result.getCity()); // 深圳市
System.out.println(result.getDistrict()); // 南山区
System.out.println(result.getStreet()); // 科技园路第四步:搭建查询服务
将IP查询封装为内部HTTP或gRPC服务,供各业务系统调用。以Python Flask为例:
from flask import Flask, request, jsonify
from ipdb import IPDatabase
app = Flask(__name__)
db = IPDatabase("/data/ipdb/ipv4_street.dat")
@app.route("/api/ip/query")
def query_ip():
ip = request.args.get("ip")
result = db.query(ip)
return jsonify({
"country": result.country,
"province": result.province,
"city": result.city,
"district": result.district,
"street": result.street,
"isp": result.isp
})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)第五步:建立更新机制
设置定时任务,每隔1-3个月从服务商下载最新离线库文件。更新策略建议采用"灰度切换":先在预发布环境验证新版IP库的查询一致性和性能,确认无异常后,再切换至生产环境,降低更新风险。
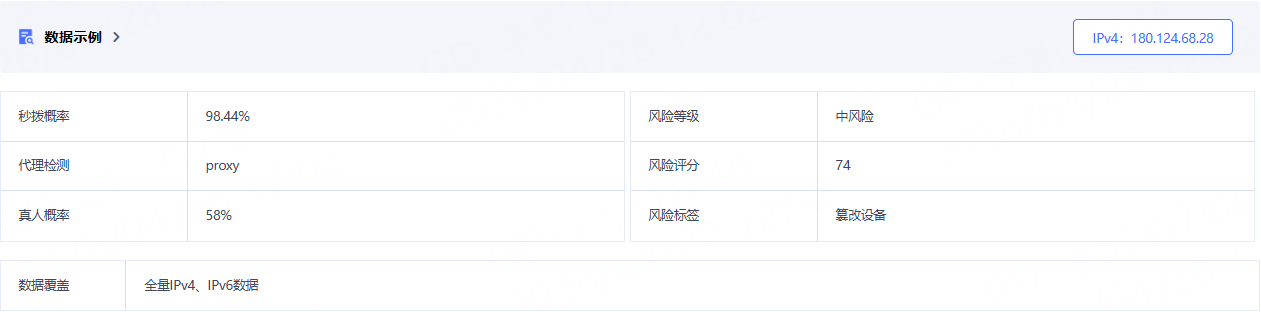
IP欺诈风险查询的落地方式
有了街道级IP定位和离线库部署,IP欺诈风险查询的实现路径就清晰了。以下是几个典型的风控规则示例:
规则一:IP定位与收货地址地市不匹配
当用户下单时,系统实时IP欺诈风险查询,对比IP的街道级位置与收货地址的行政区划。若IP定位在深圳南山区,收货地址却填北京海淀区,且无合理解释(如代购场景),则标记为可疑订单。
规则二:IP类型与业务场景不匹配
普通个人用户的IP类型通常为"住宅宽带"或"移动网络"。若IP欺诈风险查询发现IP类型为"数据中心/机房"、"代理/VPN",且行为特征异常(如批量注册、高频下单),则触发风控拦截。
规则三:IP时空异常
结合用户历史行为记录进行IP欺诈风险查询。例如,某用户账号在10分钟内,先后从广州天河的移动网络IP和上海浦东的宽带IP登录,这种瞬时跨区域的IP跳变是盗号行为的典型特征。
规则四:IP风险评分综合判定
部分离线IP库内置风险评分字段,综合评估IP的代理可能性、黑产关联度、攻击历史等因素,输出0-100的风险分值。风控系统可根据不同业务设置不同的分数阈值,实现精细化管理。
工具推荐
IP数据云(https://ipdatacloud.com/)提供的离线IP数据库产品,覆盖全球IPv4和IPv6地址,支持从国家级到街道级IP定位的多级精度。其离线库文件为标准二进制格式,配套Java、Python、Go等多语言SDK,部署流程清晰。对于需要落地离线IP数据库部署并实现IP欺诈风险查询的企业,IP数据云的产品文档提供了详细的接入指引和部署建议。
总结
从城市级到街道级IP定位的精度跃升,配合离线IP数据库部署的本地化方案,为企业构建了一套高效、合规、低延迟的IP风控基础设施。这不仅大幅增强了IP欺诈风险查询的识别能力,也为风控团队提供了更可靠的数据底座。建议企业在评估自身查询量级、精度需求和安全合规要求的基础上,逐步落地街道级离线库部署方案,真正实现从"能用"到"好用"的IP风控能力升级。
FAQ
Q1:街道级IP定位的精度在所有地区都一样吗?
A1:不同地区的精度存在差异。在互联网基础设施完善、ISP数据质量高的城市核心区域,街道级定位效果通常较好;在偏远地区或IPv6覆盖率较低的区域,精度可能回落至区县级。建议在关键业务环节结合其他维度的数据进行综合判断。
Q2::IP欺诈风险查询的结果可以直接作为风控决策依据吗?
A2:不建议单一依赖。IP风险查询应作为风控模型的输入特征之一,结合设备指纹、行为分析、交易金额等多维数据综合判定。单一IP信号存在误判可能(如正常用户使用企业VPN),多维度交叉验证才能有效降低误伤率。
 推荐阅读
推荐阅读  延伸阅读
延伸阅读 



